Vision Transformer 里的"伪影"与"寄存器":一场模型自己发明出来的计算小把戏
2025-11-10
研究主题:Vision Transformer (ViT) 的可解释性与架构机制
📚 核心参考文献
- Darcet, T., et al. (2024). “Vision Transformers Need Registers.” ICLR 2024.
- Jiang, N., et al. (2025). “Vision Transformers Don’t Need Trained Registers.” NeurIPS 2025.
0. 从一张“奇怪的注意力图”说起
早期自监督 ViT(比如 DINO)有个很迷人的特性:
把 [CLS] 的注意力可视化之后,物体轮廓干净利落地浮现出来,几乎像“自带分割头”。
然而,当我们切换到更强的大模型——DINOv2、OpenCLIP、DeiT-III 等,注意力图开始出现一种诡异现象:
- 模型会在天空、草地、背景这些低信息区域,打出一堆高亮的注意力“斑点”;
- 看起来就像模型突然对纯色背景有了强烈兴趣。
这些就是所谓的 Attention Artifacts(注意力伪影)。
它们既破坏了可解释性,也让一票基于注意力图做下游任务的方法(比如 LOST)非常难受。
📊 图示:DINO / DINOv2 / OpenCLIP 的注意力图对比

Figure 2 (Paper 2): 展示伪影现象的出现
接下来要讲的,就是两篇论文如何把这件事从”怪现象”一路追到”具体神经元”和”理论解释”,最后还顺带给出了解决方案。
1. 伪影背后:高范数离群 Token
1.1 先看一个简单统计:Token 范数的双峰分布
Darcet 等人的工作先做了一件很朴素的事情:
在像 DINOv2 这样的模型里,把最后一层的 patch token 全部拿出来,统计它们的 L2 范数。
然后发现了两件事:
- 大多数 Token 的范数都落在一个较低的区间
- 有 2–3% 左右的 Token 范数异常之高(比如 > 150 这种等级),形成了一个单独的峰
更有趣的是,这些 高范数 Token 的空间位置,和注意力图里的”伪影斑点”高度吻合。
📊 L2 范数直方图对比
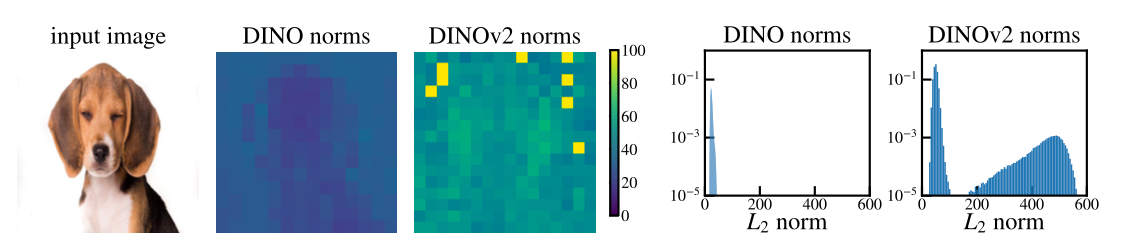
Figure 3 (Paper 2): DINO 与 DINOv2 的范数分布差异
1.2 它们喜欢“躺平的地方”
进一步的分析还发现:
- 这些高范数 Token 更常出现在信息冗余的背景区域
- 比如大片相似的草地、天空、墙面——也就是”你不看也没啥”的区域
📊 范数随层数/模型大小变化
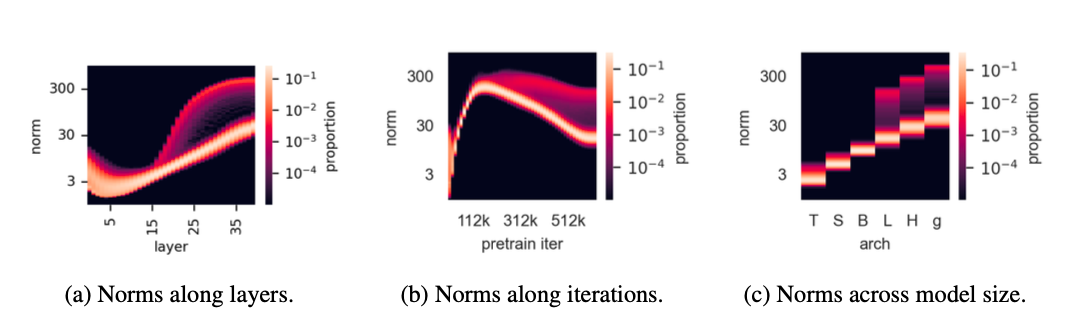
Figure 4 (Paper 2)
📊 邻居相似度分布对比
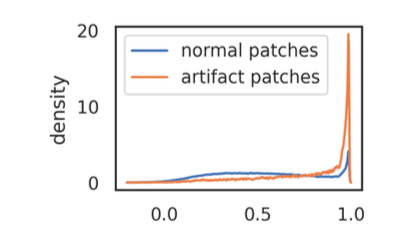
Figure 5a (Paper 2): 伪影 vs 正常 patch
所以直觉图景大概是:
💡 关键洞察:模型似乎在用这些”背景 patch”做某种别的事,而不是老老实实表示像素。
2. 这些 Token 里到底装了什么?——探针实验的答案
Darcet 做了两组很干净的探针实验:本地信息 vs 全局信息。
2.1 本地信息:这些 Token 已经“不记得自己是谁”了
他们在冻结的 ViT 上训练线性探针,做两件事:
- 用单个 Token 预测它在 (16 \times 16) 网格里的原始位置;
- 用单个 Token 回归重建它对应 patch 的像素值。
结果:
- 正常 Token 表现还不错;
- 高范数离群 Token 的表现则极差——几乎恢复不了位置信息,也重建不了像素。
也就是说,从表征角度看:
⚠️ 重要发现:模型 主动抹掉了这些 Token 的本地信息。
📊 本地信息探针表现对比
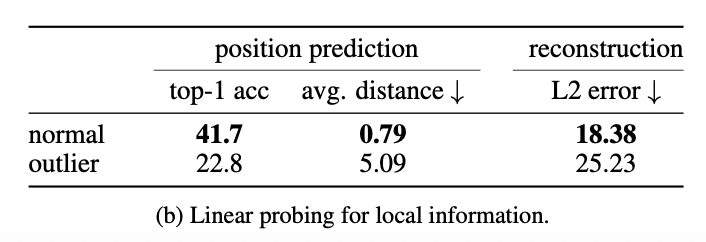
Figure 5b (Paper 2): 高范数 Token 无法恢复位置和像素信息
2.2 全局信息:它们却非常“知道整张图在干嘛”
接着,作者又做了一个“反直觉”的操作:
- 从一张图里只采样一个 Token(要么是高范数 Token,要么是普通 Token);
- 用这个 Token 的表征去做 ImageNet 线性分类。
结果:
- 高范数 Token 的分类准确率明显高于普通 Token
- 甚至可以接近
[CLS]Token 的效果
📊 全局分类探针准确率对比
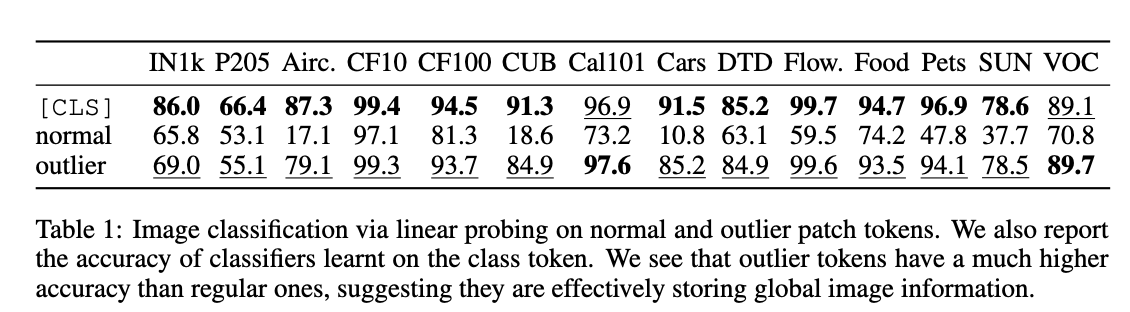
Table 1 (Paper 2): 高范数 Token 的全局信息保持能力
于是一个很形象的结论出现了:
🎯 核心结论:这些离群 Token 已经不再”代表原 patch”,而是被模型”征用”成了某种全局信息存储单元。
Darcet 把它们叫做 “Registers(寄存器)” ——一块被模型从图像上”挖走”出来当 scratchpad 用的记事本。
3. 解决方式(一):给模型显式发几个“寄存器 Token”
既然模型自己在偷用背景 patch 做寄存器,那一个自然的想法是:
干脆在输入里显式多加几个寄存器 Token,
告诉模型:“你要 scratchpad,就用这几个,不要动图像 patch。”
3.1 架构改动:加几个 [REG] Tokens
具体做法:
- 在输入序列中,除了
[CLS]和 patch tokens,再加上 N 个可学习的[REG]Tokens - 这些 Token 在所有 Transformer 层中一起参与计算
- 最后输出时,直接丢弃这些
[REG]的表征,不用在任何任务上
🏗️ 架构示意图:带 Registers 的 ViT
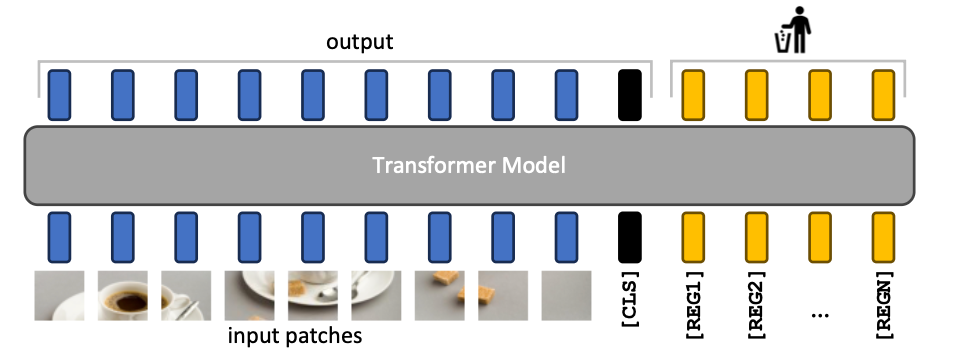
Figure 6 (Paper 2): 显式加入寄存器 Token 的架构设计
3.2 效果:伪影从 patch 上“消失”,被吸进 [REG] 里
重新训练后的结果:
- ✅ patch 的高范数伪影现象消失
- ✅ 高范数集中出现在
[REG]Tokens 上 - ✅ 注意力图恢复成干净、语义友好的样子
- ✅ 在分类、分割、深度估计等任务上,性能不降反升
- ✅ 在 LOST 这种依赖”光滑特征图”的任务上,提升尤其夸张,corloc 提升了二十多个点
📊 范数分布对比
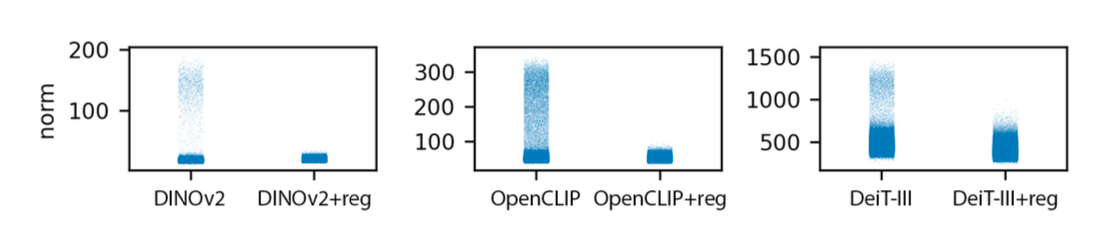
Figure 7 (Paper 2): DINOv2 vs DINOv2+reg
📊 各任务性能对比
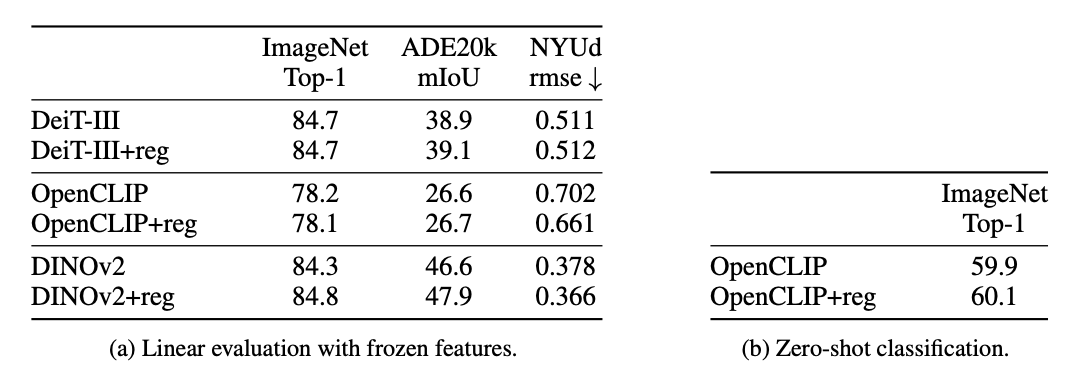
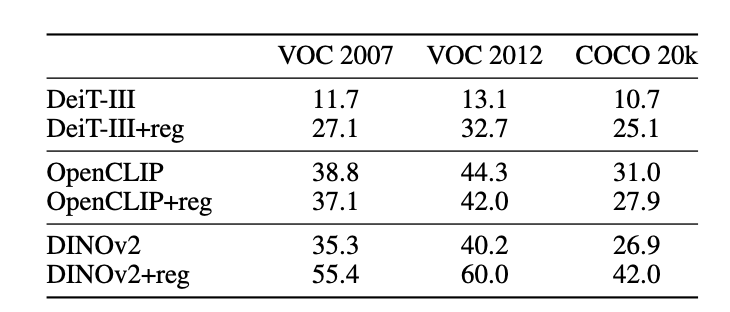
Table 2 & 3 (Paper 2): 跨任务性能提升
小结一句:
💡 Darcet 的结论:“ViT 确实需要寄存器,你不给,它就自己薅背景 patch 来用。”
问题是——要重训整个模型,成本极高。
这时,第二篇论文登场了。
4. Jiang:寄存器 Token 是怎么“算”出来的?
Darcet 给了一个“架构 + 经验”层面的解决方案,但并没完全解释:
这些高范数 Token 是怎么在计算图里生成的?
Jiang 等人的工作就是追到这个层面:
从具体层、具体神经元,一直解释到 No-Op 需求与注意力的理论结构。
4.1 观察一:高范数不是慢慢涨出来的,而是“一层蹦出来的”
他们对各层的范数做了 tracking,发现在一些模型里:
- 比如 OpenCLIP 的某一层、DINOv2 的第 17 层;
- Token 范数在 MLP 之后突然暴涨;
- 注意力模块前后,范数变化却并不明显。
进一步拆解 MLP 的激活,发现:
- 真正导致范数爆炸的,只是少数几个神经元;
- 比如某一层的 5–10 个神经元,在 specific patches 上激活极高。
于是,这一小撮神经元被命名为:
🔬 Register Neurons(寄存器神经元)
📊 Attention vs MLP 范数变化
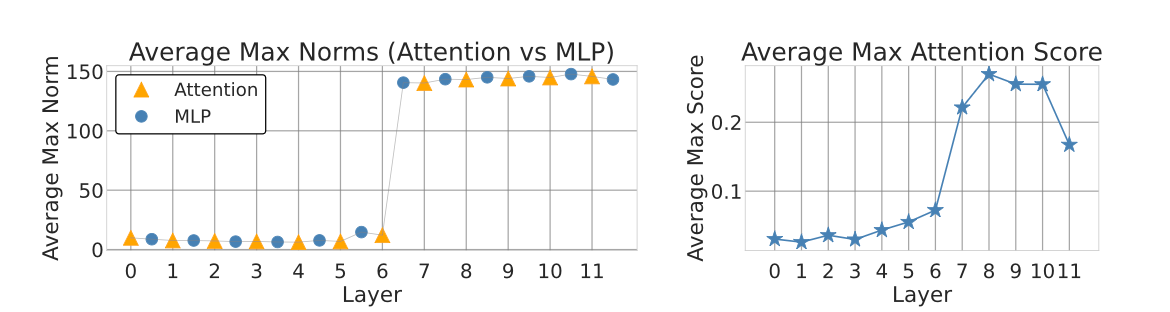
Figure 2 (Paper 1): MLP 层导致范数突然暴涨
📊 寄存器神经元激活 vs 伪影位置
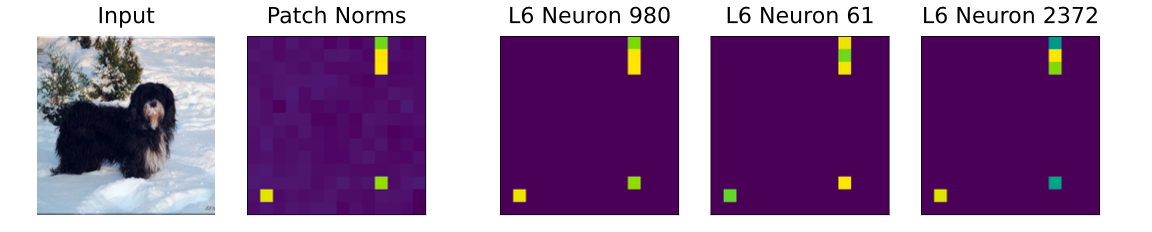
Figure 3 (Paper 1): 激活位置高度吻合
4.2 因果干预:用几个人工操作,把伪影拼成“笑脸”
为了证明这几颗神经元真是“元凶”,Jiang 做了一个非常直观的因果实验:
- 在前向传播时,把寄存器神经元在所有 patch 上的激活拿出来;
- 把“最大激活值”复制到指定位置(比如组成一个笑脸形状);
- 把其他位置清零;
- 再去看注意力图。
结果:
🎭 惊人效果:伪影的位置完全被他们控制,想画笑脸有笑脸,想画爱心有爱心。
🎨 因果干预实验:“笑脸”与”爱心”控制
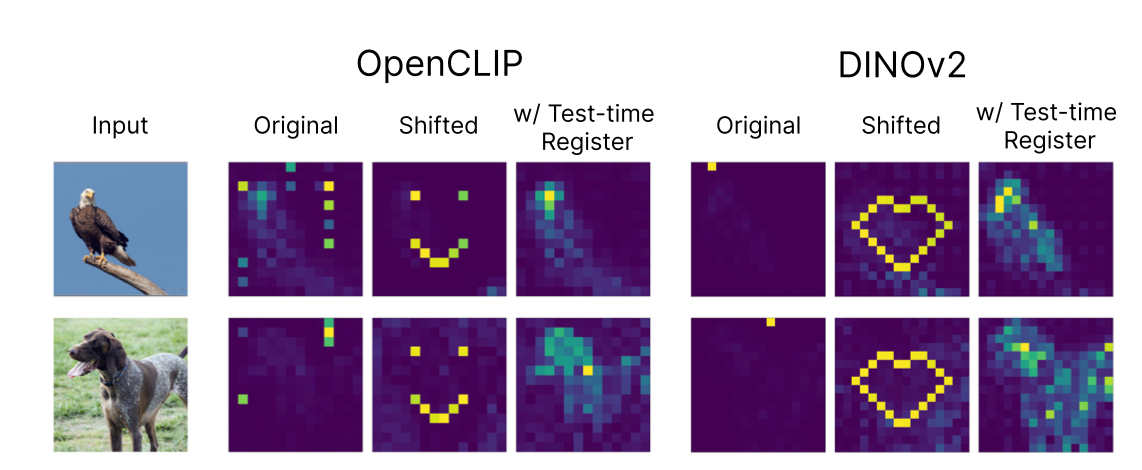
Figure 1 (Paper 1): 通过操控寄存器神经元精确控制伪影位置
从因果角度,这等于给出了非常强的证据:
✅ 因果证明:寄存器神经元是伪影(高范数 Token)的直接生成机制。
5. 为何需要这样的机制?——注意力汇与 No-Op
接下来就到了“理论解释”环节。
5.1 Attention 的困境:Softmax + No-Op
Transformer 里有两个约束:
- 注意力用 Softmax,每一行的注意力权重之和必须等于 1;
- 但某些 Token(尤其是
[CLS]或一些已经编码完的 Token)会有一种“诉求”:“我现在的表示已经很好了,我不想再从别人那儿读信息了。”
这就是所谓的 No-Op(不更新) 需求。
问题来了:
- 要 No-Op,意味着这个 Token 在某一层里“最好别认真看任何人”;
- 但 Softmax 强制它必须对某些 Token 给出高权重。
解决这个矛盾的自然方式就是:
造一个专门的 Token,当成注意力的“垃圾桶”。
所有“不想看的注意力”都丢给它。
这个垃圾桶 Token,就是 Attention Sink(注意力汇)。
5.2 寄存器神经元在干嘛?
Jiang 的解释是:
- 寄存器神经元通过在某些 patch 上制造高范数表征;
- 让这些 patch 和
[CLS]等 Token 的点积变得特别大; - 从而在 Softmax 里成为非常稳定的“吸注意力对象”。
更关键的一点:
- 这些高范数 Token 的方向被约束在下游任务头的核空间 (Kernel Space) 中;
- 也就是说,它们在后面任务头里基本被“乘成零”,不影响输出。
换句话说:
它们在注意力空间里是“黑洞”,
在任务空间里是“透明的”。
Jiang 进一步从数学上证明:
📐 数学等价性:这种”寄存器神经元 + 高范数 Token”的组合,等价于在注意力里显式加上一个偏置项。
📐 Attention Bias 等价形式
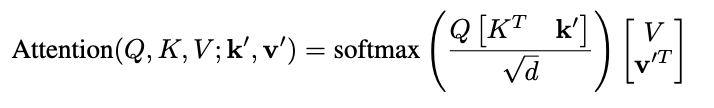
Equation (1) & Figure 7 (Paper 1): 数学证明等价关系
5.3 如果把寄存器神经元“堵死”会怎样?
一个简单但残酷的实验:
- 把寄存器神经元的激活全部清零;
- 不做任何别的补救。
结果:
- OpenCLIP 在 ImageNet 上的 zero-shot 精度,从 70.4% 掉到 55.6%;
- 但如果清零同数量的随机神经元,性能几乎不变。
结论非常直接:
这些伪影背后的高范数机制,不是 bug,而是模型算子的一部分。
你不能直接把它关掉,只能想办法重新疏导。
6. 解决方式(二):免训练的修复方案
理解了机制之后,Jiang 提出了两个“不用重训”的方案:
- 测试时寄存器(Test-Time Register)
- 注意力偏置(Attention Bias)
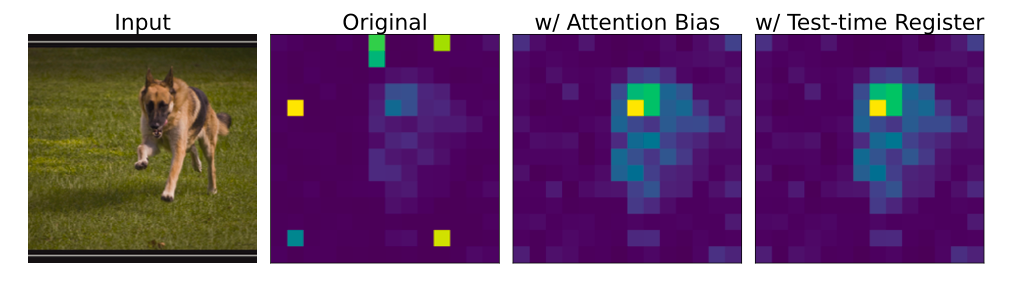
6.1 流程 A:测试时寄存器(Test-Time Register)
思路:既然寄存器神经元必需,但它们的位置可以调整,那可以这样:
- 在推理时额外加一个“临时寄存器 Token”(比如全零向量);
- 在指定层,检测寄存器神经元的激活;
- 对每个寄存器神经元:
- 找到激活的最大值;
- 把这个值“剪切”到临时寄存器 Token 上;
- 把所有 patch 上该神经元的激活清零;
- 之后正常前向。
这就相当于说:
🔧 核心思路:寄存器神经元还在工作,但它们只把信息写到”专用寄存器 Token”里,而不是在背景 patch 上”乱画伪影”。
⚙️ Test-Time Register 流程
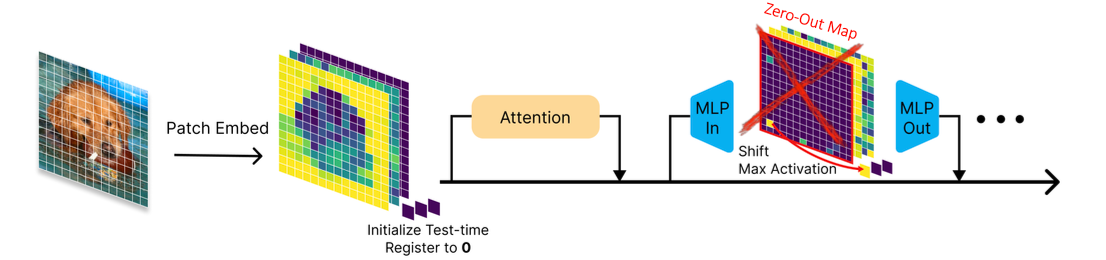

Figure 11 & Algorithm 2 (Paper 1): 推理时动态重定向寄存器激活
6.2 流程 B:注意力偏置(Attention Bias)
注意到 Test-Time Register 的本质是在构造一个“有效偏置”。
于是可以进一步把操作“压缩”为:
- 用少量校准数据(比如 1000 张图),在 Test-Time Register 设置下跑一遍;
- 估计出对应的注意力偏置向量 ((k’, v’));
- 在推理时:
- 直接把寄存器神经元清零;
- 在注意力计算中显式注入 ((k’, v’))。
⚙️ Attention Bias 效果示意
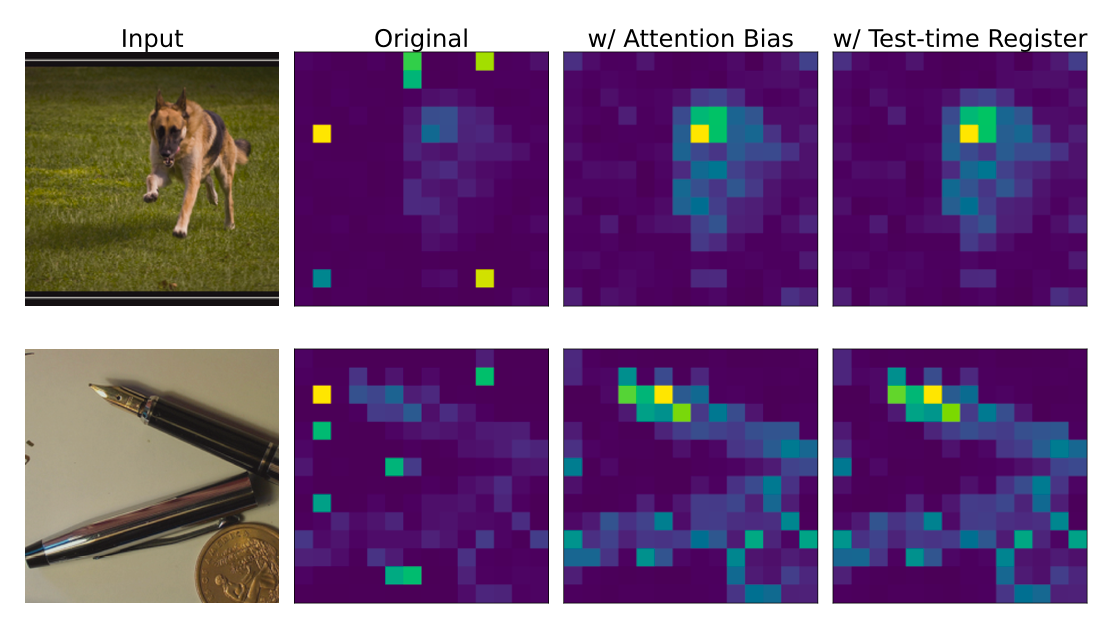
Figure 9 (Paper 1): 注意力偏置的应用效果
这一步相当于:
🎯 优化策略:把一个”动态的寄存器机制”浓缩成一个”固定的注意力偏置”。
6.3 效果与对比
实验表明:
- ✅ 在分类、分割、深度估计、LOST 等任务上
- ✅ 这两种免训练方案的表现,可以和 Darcet 的”重训寄存器 ViT” 相当
- ✅ 在多模态模型(如 LLaVA)上,也能大幅改善跨模态注意力中的伪影,使归因更合理
📊 性能对比表
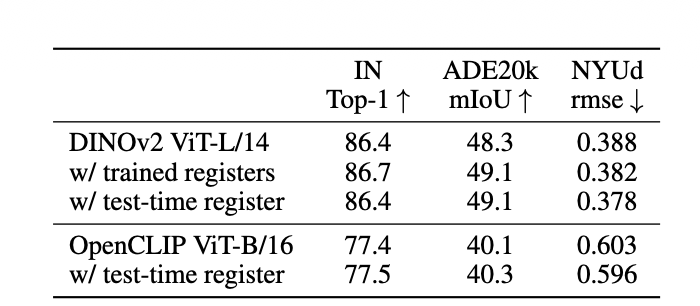
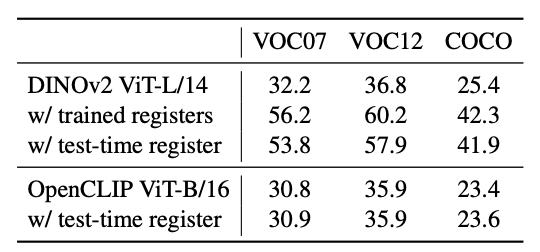
Table 2 & 5 (Paper 1): DINOv2 原版 vs Trained Reg vs Test-Time Reg
📊 VLM 伪影修复效果
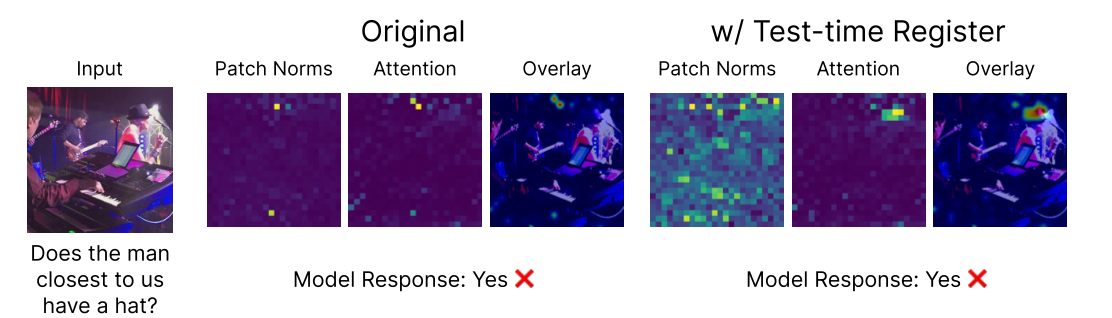

Figure 6 & 32 (Paper 1): 多模态模型的归因改善
7. 两篇论文的关系:从“症状”到“机制”再到“低成本治疗”
可以把两篇论文看成同一个故事的两个章节:
| 🔍 视角 | 📄 Darcet, 2024 | 📄 Jiang, 2025 |
|---|---|---|
| 发现 | 注意力伪影 + 高范数离群 Token | 伪影由少量寄存器神经元在特定 MLP 层触发 |
| 解释 | 模型会”征用背景 patch 当寄存器” | 这些寄存器实现了 Attention Sink + No-Op 需求 |
| 方案 | 显式加 Trained Registers(重训) | 推理时寄存器 / Attention Bias(免训练) |
| 成本 | 🔴 高:要从头训练模型 | 🟢 低:对现有模型即插即用 |
| 贡献 | 定义问题,提出”Vision Transformers Need Registers” | 说明”Don’t Need Trained Registers,机制本身已经在了” |
从可解释性的视角,这是一个非常完整的闭环:
🔄 完整的研究闭环
- 🔍 发现现象:注意力伪影 → 可解释性退化
- 📊 量化问题:高范数离群 Token → 统计结构
- 🧪 功能分析:本地信息消失 / 全局信息增强
- 💡 提出假说:Token 被 repurpose 为寄存器
- 🔬 机制追踪:具体到某一层的少量寄存器神经元
- 📐 理论建模:Attention Sink、No-Op、Kernel Space、Attention Bias 等价
- 🛠️ 设计修复:从”重训架构”到”免训练 patch”
也算是一个很标准的:
🎓 经典范例:“从奇怪可视化 → 深入模型内部机制 → 反向指导架构与推理修复” 的可解释性研究范式。
主题: ViT based视觉编码器, 训练动态